Я создаю реактивные, полностью асинхронные, высокопроизводительные, мультиплатформенные приложения уже несколько лет. За это время я столкнулся с несколькими сложными, трудноуловимыми, тяжелыми для отладки проблемами с управлением состоянием. В этой статье я хочу поделиться с вами своим опытом, чтобы, надеюсь, вам не пришлось проходить через те же проблемы, через которые прошел я, и чтобы предложить новый подход к управлению состоянием, которого я никогда раньше не видел и который избавит вас от этих проблем навсегда.
История начинается с того момента, когда реактивные приложения, использующие MVI / MVVM+, стали популярными, и я начал делать первые шаги в обучении их созданию. В этой статье я в основном буду говорить о MVI, потому что управление состоянием в MVI немного более продвинутое, поэтому примеры будут более наглядными, но те же проблемы и решения применимы к MVVM (в котором тоже есть состояние(я) для управления).
Помните то время, когда Unidirectional Data Flow (UDF) стал модным, и мы все начали его использовать? То время породило очень характерные баги в некоторых приложениях, которые я назову “проблемой несогласованного состояния”. Позвольте показать вам реальный пример:
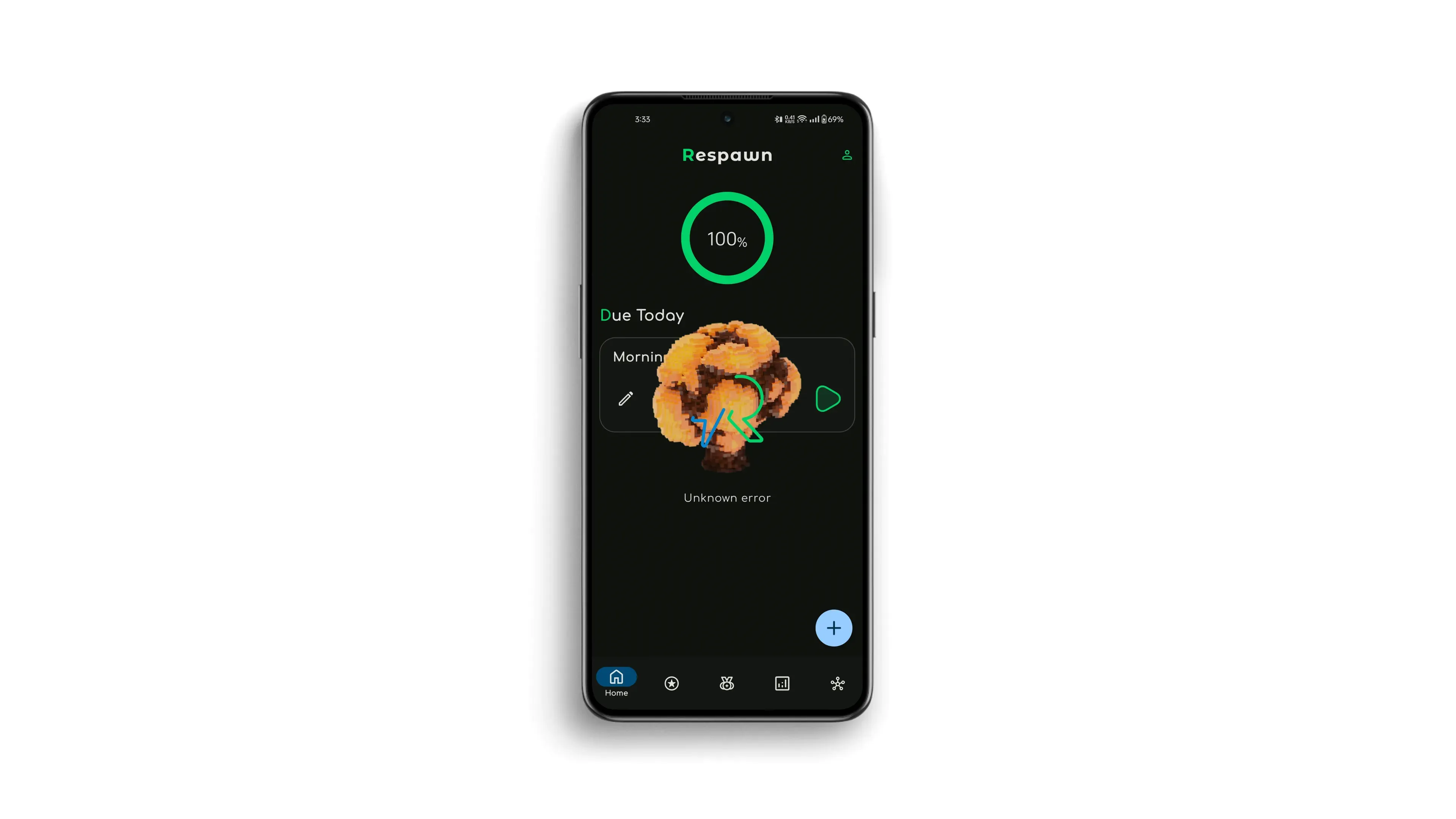
Видите это? Приложение отображает состояния Loading, Error и Success одновременно. Я уверен, вы сталкивались или скоро столкнетесь с чем-то подобным при работе с UDF.
В этой статье мы собираемся решить эту проблему навсегда.
Начнем: Что такое состояние? Что такое транзакция состояния?
Давайте начнем с изучения того, что такое состояние в контексте этой статьи и что такое “транзакции состояния”.
Я определяю состояние приложения как:
Объект или несколько объектов, которые хранятся в памяти и представляют условие приложения в данный момент времени, служа цели хранения снимка данных, необходимых для функциональности приложения.
Проще говоря, это означает, что я определяю состояние как:
Класс, который представляет самые свежие данные, которые приложение получило из нескольких источников истины
Пример состояния, с которым вы, вероятно, наиболее знакомы - это состояние UI:
data class UIState(
val isLoading: Boolean = true,
val error: Exception? = null,
val items: List<Item>? = null,
)Обычно каждая страница (экран) нашего приложения имеет свое собственное состояние UI. Иногда состояние может быть разделено между разными компонентами (например, виджетами) приложения. Но что такое “транзакция” состояния?
Транзакция состояния - это атомарная операция, которая изменяет текущее состояние приложения.
Транзакции состояния происходят постоянно. Всякий раз, когда вы хотите загрузить элементы из интернета или базы данных, например, вы хотите сделать 3 вещи:
- Установить состояние для показа индикатора загрузки
- Запросить элементы из источника данных и дождаться их прибытия
- Установить состояние для отображения элементов
Здесь минимальное количество транзакций, которое вы должны выполнить, - две: одну для установки состояния загрузки и одну для установки состояния отображения элементов.
Причина, по которой нам нужны транзакции состояния, заключается в том, что наше состояние по умолчанию независимо от состояния источника данных. Это означает, что новые данные могут прийти в базу данных, но наше состояние не изменится, и вы будете показывать устаревшую информацию, если не сделаете что-то с этим вручную. Я ниже расскажу о том, как решить эту проблему.
Теперь давайте разберемся с разницей между персистентными и транзиентными состояниями.
Я определяю персистентное состояние как:
Состояние приложения, которое не зависит от жизненного цикла процесса приложения.
Примеры - это базы данных, бэкенд, SavedStateHandle (на Android) и файлы. Все они имеют одну общую черту - они переживают жизненный цикл нашего запущенного приложения.
Соответственно, транзиентное состояние - это:
Состояние приложения, которое существует, пока процесс приложения жив, то есть состояние, которое хранится в памяти.
Примеры - это видимость индикатора загрузки, состояния ввода текста или клиент-серверные сессии и соединения.
Согласно моему определению, приложения могут работать только с использованием транзиентных состояний. Это означает, что мы не можем использовать состояние базы данных напрямую - мы должны наблюдать за ним и реагировать на его изменения, надеясь, что наше транзиентное состояние синхронизировано с состоянием базы данных. Можете угадать, где теперь могут возникнуть проблемы?
Прежде чем мы продолжим, последнее, что нам нужно прояснить, - это как мы можем определить транзиентные состояния в нашем коде.
Первый метод, используемый в MVI, - это хранить один объект состояния, который представляет “сборище” данных из разных источников и транзиентных суб-состояний. Проще говоря, у нас есть только один объект состояния на компонент бизнес-логики (BLoC). Пример такого состояния был продемонстрирован выше.
Второй метод используется в MVVM - это иметь несколько независимых объектов состояния, которые изменяются отдельно, в рамках одного блока бизнес-логики. Пример этого будет:
val isLoading = MutableStateFlow<Boolean>(true)
val error = MutableStateFlow<Exception?>(null)
val items = MutableStateFlow<List<Item>?>(null)Не поймите меня неправильно - мы всегда должны декомпозировать состояния, будь то MVI или MVVM. Мы просто делаем это менее детально с MVI, объединяя наши состояния внутри компонента бизнес-логики (BLoC). Читайте дальше, чтобы получить объяснение почему мы можем захотеть это сделать.
Шаг 1: Делаем состояние реактивным
С UDF наша цель - сделать состояние приложения зависимым от состояния источника данных.
Например, вместо ручного управления состоянием для отображения элементов (шаг 3), мы можем следить за изменениями в состоянии базы данных, и когда придут новые данные, мы автоматически обновим состояние этими данными. В нашем примере мы можем сделать это с помощью триггеров базы данных, которые обычно есть в ORM. Обратите внимание - мы не устранили транзакцию из примера выше, мы просто сделали ее автоматической, отвязанной от нашей логики.
Таким образом, с точки зрения клиента (разработчика), наш поток теперь выглядит так:
- Установить состояние для показа индикатора загрузки
“А где остальное?” - можете спросить вы. На мой взгляд, это самое большое обещание UDF - мы доверяем, что наше состояние всегда будет приходить из надежного источника данных, так что нам не придется управлять им самостоятельно. В нашем случае нам просто нужно “начать” с индикатора загрузки, а наш триггер базы данных сделает остальное, запросив новые данные и отслеживая их изменения. Когда данные загрузятся, какая-то другая часть нашего кода установит наше транзиентное состояние в соответствие с персистентным. Мы можем сделать то же самое с сетевыми запросами, обернув их в реактивные потоки, такие как Cold Flows в Coroutines:
val items = flow {
api.getLatestItems()
}Когда мы подпишемся на наш flow, фреймворк лениво выполнит наш запрос и получит данные один раз, затем будет использовать их повторно, пока мы не покинем жизненный цикл нашего BLoC.
В случае состояния, которое не обновляется источником данных (оно изначально и полностью транзиентное), мы можем просто создать наблюдаемый объект, такой как горячий Flow, и изменять его, когда данные меняются, вручную. Наши клиенты будут уведомлены об изменении так же, как и с персистентным состоянием. В этом случае мы как бы сами себе триггер базы данных.
val username = MutableStateFlow<String>("")
fun onUsernameChanged(value: String) {
username.value = value
}Вместо того чтобы изменять состояние напрямую, мы изменяем значение наблюдаемого потока, подключаясь к действиям, которые пользователь выполняет в UI, и делегируем изменения для хранения в нашем поле username.
Шаг 2: Объединение состояний
Теперь позвольте мне рассказать о том, почему мы можем захотеть объединить наше состояние и когда нам этого не следует делать.
Состояние обычно объединяется с MVI, и мы делаем это по следующим причинам:
- Мы даем единую, четко определенную точку доступа к состоянию нашего приложения, готовую к использованию клиентами
- Мы явно определяем все связанные изменения состояния в рамках одной транзакции (и, как результат, в рамках одного легкого для понимания блока кода)
- Мы сокращаем количество транзакций состояния, когда может измениться много переменных, получая производительность
- Мы делаем использование и изменение связанных состояний проще, группируя их свойства вместе
- Мы защищаем себя от доступа к данным, к которым у нас никогда не должно было быть доступа, на этапе компиляции
Для меня самое большое преимущество - это #5. Если мы правильно объединим наши состояния, мы можем быть уверены, что не получим доступ к тому, к чему не должны были, еще до того, как скомпилируем наше приложение.
Посмотрите на пример MVVM сверху:
val isLoading = MutableStateFlow<Boolean>(true)
val error = MutableStateFlow<Exception?>(null)
val items = MutableStateFlow<List<Item>?>(null)Видите ли вы теперь здесь проблему? Мы должны объявить кучу переменных, которые null или “пустые”, потому что очень часто их просто нет. Нам также приходится учитывать тот факт, что список элементов может быть не только пустым, но и отсутствующим.
На мой скромный взгляд, это сильно усложняет нашу бизнес-логику:
- Мы всегда должны проверять, присутствует ли значение, даже если мы уверены, что оно будет присутствовать в каком-то конкретном месте
- Мы должны всегда хранить ссылки на значения, несмотря на то, что они нам нужны нечасто
- Мы должны всегда следить за тем, чтобы очищать каждое отдельное значение при каждой манипуляции состоянием, чтобы уведомить наш код, что значение пропало, и поддерживать согласованность нашего UI
- Мы должны передавать все эти значения в наш UI и управлять ими там, усложняя наш код. Нам также приходится поддерживать получающийся бойлерплейт
Это основные причины, по которым я предпочитаю объединять свои состояния при использовании MVI. Это также, вероятно, причина, по которой Google (и большинство коммерческих современных приложений вместе с ним) отходят от традиционного MVVM и движутся к MVVM+ (который такой же, но имеет объединенные состояния).
Вы можете сказать: “Но я могу создать один класс, и у него все равно будут те же проблемы!” ссылаясь на мой первый пример:
data class UIState(
val isLoading: Boolean = true,
val error: Exception? = null,
val items: List<Item>? = null,
)Вот где я предлагаю новую парадигму для описания вашего состояния, используя силу языка программирования - перейти к семействам состояний, как я их называю.
Шаг 3: Делаем состояние согласованным с семействами состояний
По сути, термин “семейство состояний” означает, что:
Мы определяем состояние приложения как закрытый список различных, несвязанных объектов, представляющих текущий тип состояния нашего приложения.
В Kotlin это будет означать, что мы определим наше состояние как sealed interface и удалим все свойства, которые не могут присутствовать, когда приложение находится в этом состоянии, из результирующего объекта:
internal sealed interface EditProfileState {
data object Loading : EditProfileState
data class Error(val e: Exception?) : EditProfileState
data object Success : EditProfileState
data object DisplayingAccountDeleted : EditProfileState
data class EditingProfile(
val email: String,
val name: Input,
) : EditProfileState
}Почему я называю это “полу-” автоматами состояний или “семействами состояний”, так это потому, что в отличие от строгих автоматов, мы не определяем переходы между состояниями, так как их может быть слишком много. Это часто не нужно в клиентских приложениях (но можно легко добавить по желанию). Уже видите преимущества подхода?
- Когда мы отображаем состояние
Loading, мы уверены, что нет ни данных, ни ошибок, и никогда не будет. Мы не можем получить доступ к этим значениям, чтобы случайно показать их нашим пользователям или манипулировать ими, на этапе компиляции. - Когда мы показываем состояния
ErrorилиEditingProfile, у нас больше нет бессмысленных нуллабельных полей. Когда состояние -Error, мы на 100% уверены, что есть ошибка для отображения и ничего больше. - Наше состояние сгруппировано в одном месте, строго определено, и имеет четко определенный контракт о том, что должно присутствовать, что должно отсутствовать, и что опционально, когда мы представляем конкретное состояние.
- Мы можем иметь столько состояний, сколько хотим, мы можем иметь “вложенные состояния”, и мы можем создавать это семейство состояний, используя любую комбинацию источников данных (даже используя наш старый код, где у нас была куча flow!)
Уже лучше, правда? Вот что мы достигли нашей сменой парадигмы:
- Сначала мы резко сократили количество состояний и транзакций состояния, используя UDF и реактивные обновления.
- Затем мы объединили наше состояние, тем самым упростив нашу бизнес-логику, сделав наш код проще для понимания и расширения, и сократив количество багов, удалив все точки доступа к состоянию нашего приложения и связанным транзакциям, кроме одной
- Наконец, мы определили наше состояние как закрытое семейство типов, устранив все риски доступа к конкретным значениям, когда не следует, как в бизнес-логике, так и в клиентской (то есть UI) логике. Мы также получили визуальную, простую для понимания структуру кода и единое место, где мы можем хранить и управлять всеми нашими транзакциями состояний и значениями.
К сожалению, этот подход не без недостатков. Теперь у нас на руках две другие проблемы…
Решение проблемы #1: Потерянная информация
Поскольку теперь у нас есть единственный источник истины и отдельное семейство состояний, мы больше не можем “сохранять” наши предыдущие значения, когда состояние меняется.
Например, наше состояние Loading не содержит email или имя. Всякий раз, когда мы хотим показать индикатор загрузки для валидации нового имени пользователя, например, мы теряем всю информацию о предыдущем состоянии приложения.
Эта проблема может быть решена очень легко путем передачи состояния любому коду, который может захотеть восстановить состояние до предыдущего значения или использовать его для своих нужд, но это требует небольшого сдвига парадигмы в нашем мышлении. Когда мы теперь хотим валидировать имя, нам нужно будет передать предыдущее состояние вниз по иерархии вызовов:
val state = MutableStateFlow<EditProfileState>(Loading)
fun onSaveChangesClicked(state: EditingProfile) {
state.value = Loading
validateNameAsync(state)
}
fun showValidationError(e: Exception) { }
fun validateNameAsync(previous: EditingProfile) = launch {
try {
repository.verifyNameIsUnique(previous.name)
state.value = Success
} catch (e: Exception) {
state.value = previous
showValidationError(e)
}
}Видите? Теперь мы захватываем состояние, когда начинаем операцию, запускаем ее асинхронно, и затем устанавливаем состояние в Loading. Наша операция может показать либо Success в зависимости от результата, либо отобразить ошибку валидации и восстановить состояние до previous, используя переданный параметр.
Решение проблемы #2: Управление типом объекта
Kotlin - это статически типизированный язык, и из-за этого нам нужно безопасно приводить состояние к конкретному значению, чтобы быть уверенными, что не крашнем приложение. Нам нужно приведение, потому что иногда мы хотим получить доступ к некоторым свойствам предыдущего состояния, если они присутствуют.
Например, всякий раз, когда мы хотим обновить текущее состояние новыми данными из внешнего источника (помните про UDF выше?), мы не знаем, какое текущее состояние. Синтаксис Kotlin довольно бесячий в этом случае, но, делая все это, мы явно следуем нашему контракту во время компиляции и, таким образом, получаем преимущества наших предыдущих улучшений. Например:
class EditProfileContainer(
private val repo: UserRepository,
) {
val state = MutableStateFlow<EditProfileState>(Loading)
override suspend fun onSubscribed() {
repo.getUserProfileFlow().collect { user: User ->
state.update { state: EditProfileState ->
val current = state as? EditingProfile
EditingProfile(
email = user.email,
name = current?.name ?: Input.Valid(user.name ?: ""),
)
}
}
}
fun onNameChange(value: String) {
state.value = (state.value as? EditingProfile)?.let {
it.copy(name = Input.Valid(value))
} ?: state.value
}
}ВАЖНО: мы должны следить за изменениями персистентного состояния только когда пользователь видит экран, а не в фоне. Иначе мы тратим ресурсы впустую, и пользователь может никогда не увидеть изменения. Это требование новое, оно появилось потому, что наше состояние теперь - горячий поток данных и требует кастомной реализации обработки жизненного цикла. Если бы мы использовали там холодный flow (например, используя
combine()), нам бы это не понадобилось. Но мы хотим использовать текущее значение состояния когда угодно и приостанавливаться для его обновления, поэтому я выбрал использовать горячий flow здесь. Увеличенная сложность - это цена, которую мы должны заплатить за устранение flow и слияние их в один. Однако эта проблема не нерешаема. Если хотите, можете сделать так, чтобы свойствоstateбыло обычным полем и могло быть собрано из нескольких потоков. Я объясняю это подробно в моих других статьях.Каждый раз, когда мы получаем обновление из нашего источника данных, мы хотим использовать эти данные для перехода из состояния загрузки в новое состояние
EditingProfile. Почему? Потому что пришли новые данные, так что нет смысла оставлять индикатор загрузки. В любом случае, мы не знаем, есть ли смысл сейчас.Мы проверяем тип текущего состояния безопасно, чтобы увидеть, уже ли состояние содержит какие-то данные. В нашем примере, поле формы “Name”. Теперь мы должны безопасно обрабатывать оба случая - когда значение есть и когда его нет.
Мы собираем состояние, где мы больше не загружаемся и должны отображать данные вместо этого, но нам нужно дать необходимые значения сейчас. Иначе, если наше состояние невалидно, мы не сможем скомпилировать приложение
Теперь мы вынуждены сначала проверить, внес ли пользователь уже изменения в свое имя.
- Если да, мы просто используем предыдущее значение. Мы успешно сохранили изменения, которые сделал пользователь.
- Если нет, мы сначала проверяем, есть ли что-то в оригинальном объекте юзера. Это хороший UX - показать пользователю его предыдущее имя пользователя, если он хочет внести небольшое изменение.
- Если ни то, ни другое не присутствует, мы предлагаем пользователю добавить имя пользователя и заполняем форму ввода пустой строкой.
Если состояние не того типа, который мы хотели, мы просто пропускаем операцию. Пользователь спамил кнопками, или процессы выполняются параллельно, и состояние меняется.
Я знаю - код выше выглядит немного сложнее на первый взгляд, но я бы сказал, что мы можем легко решить и это:
- Мы можем абстрагировать логику вызовов
onSubscribe, используя или создавая архитектурный фреймворк. - Мы можем упростить визуальный вид и бойлерплейт этих приведений типов, создав хороший DSL, который будет делать всю проверку типов за нас.
- Для каждого конкретного случая использования мы можем создать простые расширения, если нам не нравится, как выглядит наш код. Например, мы могли бы создать функцию:
fun Input?.input(default: String? = null) = this ?: Input.Valid(default ?: "")
EditingProfile(
name = current?.name.input(user.name),
)Вот как выглядит мой код для этой фичи после рефакторинга:
val store = store<EditProfileState>(Loading) {
whileSubscribed {
repo.user.collect { user ->
updateState {
val current = typed<EditingProfile>()
EditingProfile(
email = user.email,
name = current?.name.input(user.name),
)
}
}
}
fun onNameChanged(value: String) = updateState<EditingProfile, _> {
copy(name = value.input())
}
}Уже не так страшно? Мое мнение - это не только получает все преимущества, о которых мы говорили раньше, но также выглядит и читается как английский, что выгодно для наших коллег по команде и для нас в долгосрочной перспективе.
Итак, теперь нам осталось решить последнюю проблему, самую коварную, о которой вы, возможно, даже не знали до сих пор.
Шаг 4: Делаем обновления состояния параллельными
Для примера, давайте скажем, что наш EditProfileContainer работает теперь в фоновом потоке и добавили валидацию ввода, которая проверяет, уникально ли имя пользователя.
fun onNameChanged(value: String) = updateState<EditingProfile, _> {
val new = copy(name = value.input())
launchValidateUsername(new)
new
}
fun launchValidateUsername(state: EditingProfile) = launch {
val unique = repo.verifyUsernameIsUnique(state.name.value)
if (!unique) updateState {
state.copy(name = Input.Error(name.value, "Username is not unique")
}
}Проблема в том, что когда пользователь редактирует свое имя и потом делает паузу, имя пользователя отправляется на проверку, но затем, если он нажимает “Submit”, порядок транзакций состояния теперь неопределен, потому что они параллельны, и мы захватили состояние, которое утекло за предеы транзакции.
Это приводит к тому, что происходит следующее, например:
- Пользователь меняет свое имя, и оно уникально
- Мы начинаем валидировать имя пользователя, но операция довольно медленная
- Пользователь сразу нажимает “Submit”
- Мы отправляем значение для сохранения и устанавливаем состояние в
Loading - Пока мы пытаемся сохранить изменения, приходит результат валидации!
- Мы обновляем состояние, чтобы восстановить предыдущее значение
- Экран пользователя мигает, и индикатор загрузки исчезает
- Пользователь, не понимая, что произошло и почему не было обратной связи, снова нажимает кнопку “Submit”.
- Мы начинаем обновлять состояние и снова показываем индикатор загрузки
- Результат предыдущего сохранения приходит как успех, и пользователь видит сообщение, что его изменения были сохранены
- Приходит результат следующего отправленного имени пользователя. Имя больше не уникально, и функция выбрасывает ошибку
- Экран мигает, и пользователь видит сообщение, что его изменения не могут быть сохранены, несмотря на то, что они были сохранены в реальности, сразу после того, как увидел сообщение об успехе
Это такой ужасный пользовательский опыт! И мы просто попытались сделать работу в фоновом потоке. Причина, по которой это произошло, заключается в том, что наши транзакции состояния не сериализуемы.
Шаг 5: Сериализуемые транзакции состояния
Термин “сериализуемый” на самом деле пришел из терминологии архитектуры баз данных (DBA) и не имеет ничего общего с REST или JSON.
Если вы не знакомы с заморочками DBA, та же проблема, с которой мы только что столкнулись, существовала давно в базах данных, так как их транзакции тоже параллельны. Одна транзакция может прочитать данные, и пока она выполняется, другая может изменить эти данные, приводя к гонке между двумя транзакциями и неопределенному результату для обеих.
Есть множество способов, которыми фреймворки баз данных решают это (и они ультра-сложные), так что мы не будем углубляться в них прямо сейчас. Если хотите узнать больше, погуглите “изоляция транзакций базы данных”. Вместо этого давайте решим эту проблему навсегда в нашем приложении.
Я исследовал эту проблему и пришел к выводу, что большинство клиентских приложений и архитектурных фреймворков используют следующие подходы:
Делать все операции последовательными
- Например, с MVI мы определяем наши Intents как очередь команд (например, с Channel), и они обрабатываются последовательно в результате. Мы уже сказали, что этот подход не подойдет для нашего высокопараллельного реактивного приложения
Использовать только Main (или один) поток для обновления состояния
- Фреймворки, такие как MVIKotlin, Orbit MVI и большинство других, используют эту стратегию, запрещая обновления состояния из фонового потока. Как мы сказали, наша цель - сделать полностью асинхронное, производительное приложение без ограничений потоков.
Разделять состояние на несколько потоков, обновляемых атомарно между потоками
- Это подход MVVM / MVVM+, но, возвращаясь к нему, мы потеряем все другие преимущества, которые только что получили
Делать все состояния персистентными - это само собой разумеется, но мы не можем покрыть все возможные варианты. Есть довольно много императивных/stateful платформенных API, с которыми нужно иметь дело.
Использовать различные флаги в состоянии для указания прогресса операций и постоянно управлять всеми ими
- Например, мы могли бы добавить флаг
isValidatingUsernameв наше состояние и проверять его, чтобы решить, переводить ли пользователя в следующее состояние или нет и/или отменять job обновления, когда мы отправляем данные - Я не считаю это решение удовлетворительным, не только потому, что мы возвращаемся туда, откуда начали, пытаясь избавиться от бессмысленных значений, но и потому, что сложность таких решений будет расти экспоненциально
- Например, мы могли бы добавить флаг
Вручную синхронизировать каждый параллельный источник данных, используя примитивы, такие как Semaphores и Mutexes
- Этот на самом деле хорош и является (спойлер) основой для нашего решения, но создавать и управлять блокировками для всего, что у нас есть, очень громоздко, и это также переносит ответственность за атомарность вниз на бизнес-логику, которая не хочет ничего знать о состояниях нашего слоя представления.
- Это также в конечном итоге замедлит наше приложение, когда мы столкнемся с обычными проблемами синхронизированного кода, такими как дедлоки, лайвлоки и голодание потоков
Я предлагаю что-то другое - почему бы нам просто не научиться у баз данных и не сделать наши транзакции состояния сериализуемыми? Реализация этого решения тоже простая:
private val _states = MutableStateFlow(initial)
val states: StateFlow<S> = _states.asStateFlow()
private val stateMutex = Mutex()
suspend fun withState(
block: suspend S.() -> Unit
) = stateMutex.withReentrantLock { block(states.value) }
suspend fun updateState(
transform: suspend S.() -> S
) = stateMutex.withReentrantLock { _states.update { transform(it) } }Мы можем извлечь этот код в делегированный интерфейс и навсегда покончить с этой проблемой.
P.S. Для тех, кто шарит, это делает наши транзакции состояния соответствующими уровню изоляции транзакций SERIALIZABLE в Postgres.
Я должен отметить, что использование блокировки с повторным входом здесь очень важно, так как мы хотим поддерживать вложенные транзакции состояния для нескольких исключений. На случай, если вы задаетесь вопросом, почему мы просто не используем _states.update { } без блокировки, вы должны прочитать документацию этого метода, чтобы понять, что функция может вызвать вашу лямбду несколько раз, если результирующее и предыдущее значения не совпадают. Мы не хотим этого для критических вызовов API, например, и в то же время мы не хотим позволять состоянию меняться, пока выполняется долгая задача. Поэтому блокировка - лучшее решение для нашего случая использования делания обновлений состояния сериализуемыми.
“И все?” - можете спросить вы.
Есть оговорка: вы должны понимать, что мы внедрили логику синхронизации в наш код, которая сделает обновления состояния последовательными по своей природе. Блокировка вносит некоторые накладные расходы по производительности каждый раз, когда мы пытаемся обновить состояние, поэтому вы можете сделать “запасную” опцию отключения сериализуемых транзакций состояния для данной операции обновления или целого BLoC, чтобы предотвратить трату ресурсов на синхронизацию, когда обновления состояния очень частые. По моему личному опыту, эти замедления редко заметны и не приведут к зависаниям, если запускаются в главном потоке.
Послесловие
Самое большое преимущество этого подхода - не решение какого-то редкого косяка, на мой взгляд, а то, что нам больше никогда не придется думать о проблемах управления состоянием, изменив парадигму, под которой мы работаем. Мы можем писать полностью асинхронный код, запускать столько параллельных процессов, сколько хотим, и создавать настолько сложные иерархии состояний и фичи, насколько хотим, все это не останавливаясь даже на секунду, чтобы сомневаться, всегда ли наш код будет вести себя, как ожидается. Использование этого подхода освободило огромное количество моих когнитивных ресурсов при создании приложений, и это в конечном итоге то, что я ценю больше всего. Я считаю, что написание кода должно быть легким, плавным процессом, где вы в идеале не должны останавливаться, чтобы рассмотреть очередное исключение или возможную проблему.
Я надеюсь, что вооруженные знаниями из этой статьи, вы теперь сможете сформировать обоснованное мнение и взять практики, описанные здесь, или реализовать идеи, которые помогут вашим приложениям стать лучше, а вашему рабочему процессу более плавным.
После прочтения этого у вас все еще может остаться пара вопросов:
- Где увидеть этот подход в действии?
- Где можно увидеть пример реализации?
- Что если я не хочу все реализовывать с нуля, а мне нужно готовое проверенное решение?
У меня всё схвачено. Все, что мы обсуждали в этой статье, я реализовал в архитектурном фреймворке.
Фреймворк:
- Делает транзакции состояния полностью сериализуемыми с блокировками с повторным входом и возможностью отключить сериализацию для одной транзакции или целого блока бизнес-логики
- Имеет хороший DSL, как тот, что выше, который упрощает проверки типов и безопасные обновления состояния
- Управляет жизненным циклом подписки за вас, чтобы запускать, останавливать и перезапускать задачи обновления состояния
- Позволяет вам делать бизнес-логику полностью асинхронной и многопоточный
- Написан на корутинах
- Делает состояния согласованными и позволяет легко объединять их в единый источник истины по дизайну
- Обрабатывает все ошибки за вас и позволяет вам обновлять состояние без
try/catchповсюду - Абстрагирует все тонкости обновлений состояния и параллельной обработки, чтобы вам не пришлось беспокоиться о них никогда
- Управляет фоновыми задачами за вас и освобождает ресурсы в правильный момент автоматически
- Поддерживает кеширование, атомарную, последовательную или параллельную обработку команд и декомпозицию бизнес-логики на асинхронные источники данных
- Сохраненяет состояния в файл по желанию
Я буду рад, если попробуете библиотеку (занимает 10 минут)!