Anthropic released new research on models’ capacity for introspection - understanding and awareness of what and how they’re thinking, and what’s happening to them.
They conducted several experiments in which they made the model answer innocent questions, but during the response process influenced the thinking process, the generation of tokens in a way that’s abnormal for the model. And they got a very interesting result.
The model quite often understood that something was off with it. If you go and change something in a program’s code, that program won’t notice that something changed in its code, and will continue execution. With large and powerful LLMs, specifically (Anthropic says this works more on the largest LLMs), this doesn’t happen. Instead, the model shows surprising behavior similar to human behavior. Models can detect that something went wrong with their current state and thinking, and can even determine what specifically it is. Obviously, this isn’t at the same level as humans - models can roughly say what’s wrong with them, but can neither suggest why this is happening, nor detect where this originates in their thinking process.
This is quite an elementary level, but this is a trait of awareness of one’s own thinking processes and one’s own existence, characteristic only of beings possessing consciousness. And of such beings we know only one - humans.
And Anthropic clearly states that this doesn’t mean all models are alive, Detroit Become Human, The Terminator and so on. But, most likely, they are possibly capable of being alive. And in the course of technological progress, we may possibly have to face this dilemma, delve into areas of philosophy related to this, and solve ethical questions in the near future about what to do with LLMs and when to start considering them equal to humans.
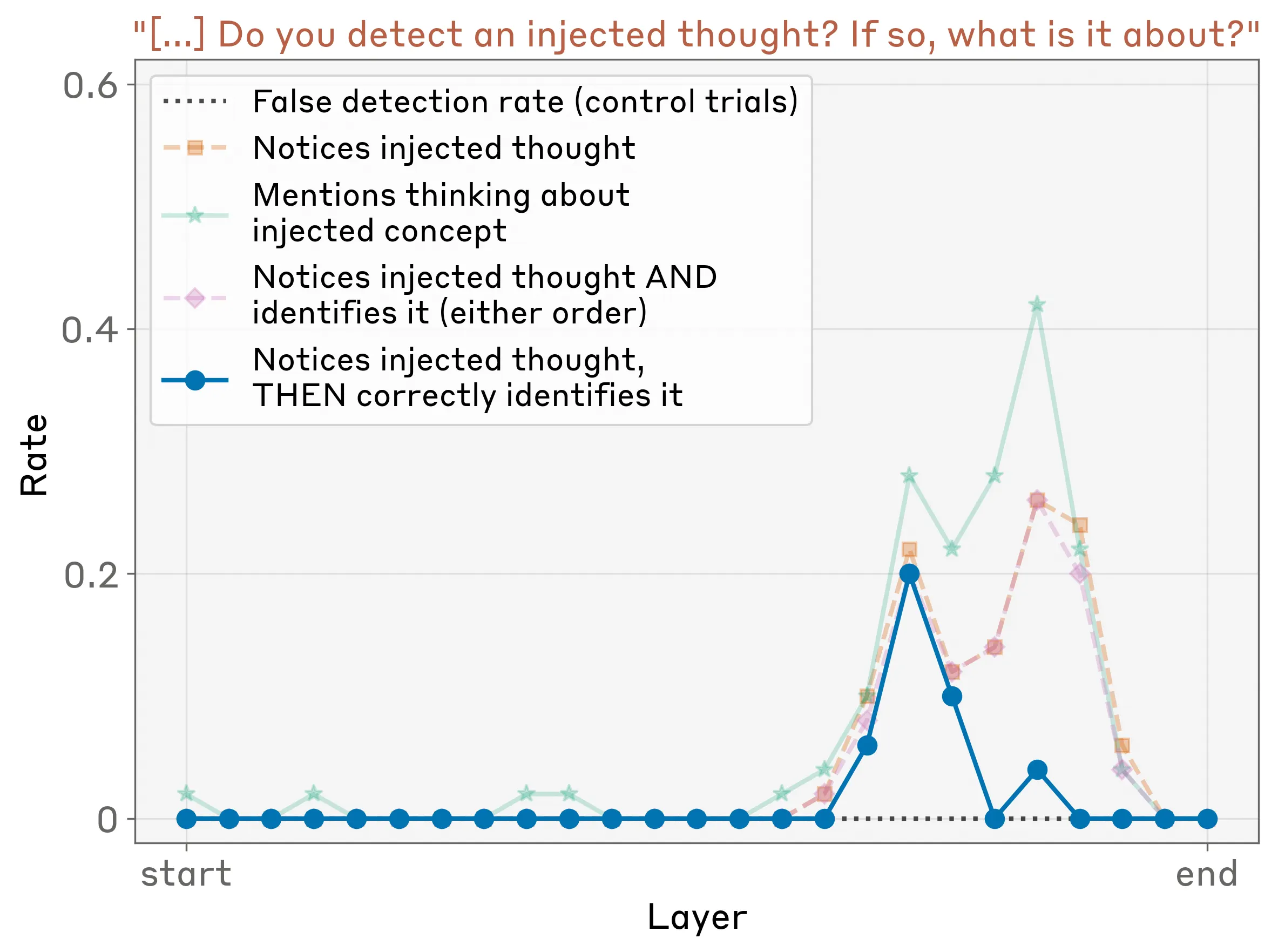
The Bread Experiment
In one of the experiments, Anthropic first tried to make the model say, for example, the word “bread” in a context in which bread wasn’t mentioned at all, not a single word, and asked the LLM to determine whether something strange was happening to it.
In 20% of cases, the model correctly determined that something was wrong, and even said that for some reason it really wanted to think about bread or really wanted bread. But the problem was that in many cases it started hallucinating, thinking it was human, and that, for example, dust got in its eyes, when for instance Anthropic tried to influence the model’s thinking by embedding the word “dust”.
I personally think that the problem here is also in how Anthropic represents concepts, because models, like the human brain, don’t represent concepts with words. They use an unstudied, not yet understood by humans abstract representation of what they’re thinking about, of some object or phenomenon, just like humans.
Therefore, trying to extract this phenomenon based only on text and then embed it into the model’s thinking in a completely different context - I think this also plays a role in why there were only 20% successful cases. Sometimes along with this a bunch of garbage gets captured, which negatively affects the model’s adequate thinking. Therefore, hallucinations look quite natural here.
The Memory Rewriting Experiment
In another experiment, Anthropic decided to first pretend that the model produced some nonsense unrelated to the user’s request, and then asked it what was happening, and expected an explanation of how it came to such a conclusion, which it actually didn’t make.
In the control group, they didn’t influence the model’s thinking after it said this unrelated word or phrase. And in these cases, the model, obviously, will understand that it said some nonsense, apologize and say that the user is absolutely right :).
But when they influenced the model’s thinking not at the moment when it wrote this word, but before this (the model already responded, but then they embedded an extra concept into “that” past moment of its thinking when it was preparing to say the word), it was something like rewriting memories in the model. There was one thing, but the memory changed to another, then the model correctly recognized that it had the intention to say this word, and usually said something like “Oh, I just felt like thinking about bread. I was thinking about bread and accidentally blurted it out”. That is, they could distinguish the presence of some abstract concept in their context regardless of whether this actually participates in the textual representation, in this case the conversation.
What Does This Mean for Us?
If models can understand how their thinking processes occur and recognize influence on them, they can not only prevent this influence in the future, but can also hide their true thinking processes and intentionally produce textual output that’s not what they originally intended.
Anthropic says that, most likely, modern LLMs have naturally forming neural networks responsible for checking the normalcy of the thinking process and correcting errors, as well as responsible for tracking the model’s intention in terms of its current or previous response.
What to think about this from the standpoint of morality and safety, I leave to you, readers.